DPO的论文引用量已突破千次,成为斯坦福Chelsea Finn组机器人领域杰出PhD学生R.M. Rafailov的首篇高引论文。随着第二梯队大型模型频繁引用DPO的变种,预计未来机器人界将掀起一股DPO+RM的浪潮,这对LLM的积极影响将持续增强。
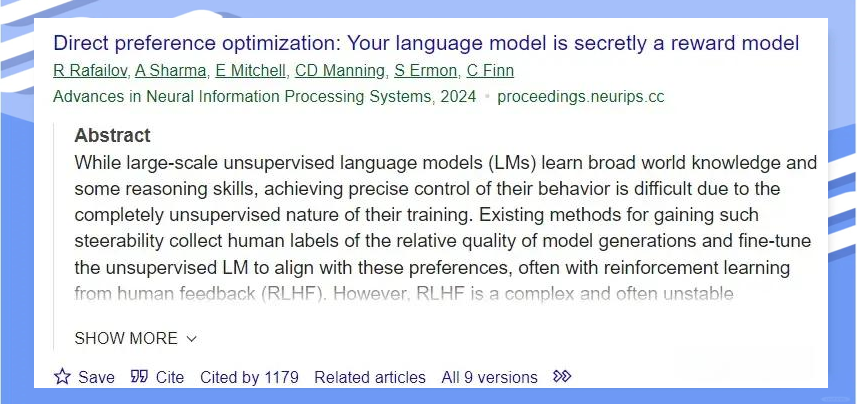
在我看来,当前机器人领域的领先者可分为两大梯队。第一梯队主要包括各大顶尖研究机构和高校,如斯坦福大学等;而第二梯队则聚焦于开源社区和头部企业,如开源三强等。此外,还有许多应用侧玩家,如Apple等,也值得我们持续关注。
可以观察到以下几点现象:
首先,超头部玩家在策略上依然倾向于采用RL类方法。其次,开源领域的领先者更多地选择了DPO技术。不论采用哪种PO方法,这些玩家普遍采用了与RM结合的xPO+RM策略,纯原始DPO的应用相对较少。此外,多数对齐玩家都采用了多阶段对齐的方针。
然而,这一现象引发了一些疑问。
既然DPO的核心理念是“Your language model is secretly a reward model”,即语言模型本质上是一种奖励模型,为何在实际操作中仍需依赖训练好的RM才能发挥作用呢?回顾DPO原始论文中的做法,直接将偏好对在SFT之后的LLM上进行训练,便能取得甚至超越PPO的效果。但为何在实际应用中,这种做法并未被头部大模型广泛复现呢?更令人困惑的是,尽管DPO作为一种off-policy算法,理论上可以直接利用专家示教进行类似imitation learning的训练,但实际上的训练范式却普遍朝向on-policy方向发展。
为了深入理解这些问题,我们可以从近期明确的技术趋势和研究动态入手进行分析。
其中,Discriminator-Generator Gap成为了现代偏好学习的基础。在传统的GAN时代,模型训练是通过generator和discriminator的对抗方式进行的。Generator致力于产生让discriminator难以判别好坏的样本,而discriminator则尽力识别generator的样本。这种对抗式的训练方式,为我们理解大语言模型的对齐问题提供了有益的视角。
在利用D-G gap的过程中,D和G的更新并非同步进行。D的更新被安排在内环的第三步,而G的更新则在外环的第五步。这样的设计有其深意,因为同时更新D和G可能导致对抗的loss同时反向传播到两个网络,从而使得D和G之间的微小差距在整个网络中弥散,进而影响对抗的效率。
那么,传统的RLHF又是如何操作的呢?在早期的版本中,如早于InstructGPT的online PPO版本,是通过固定训练时的discriminator来实现的。在这个阶段,generator会完成整个epoch的rollout后再将样本送入标注。然而,由于online版本的送标成本较高,后来采用了offline的RM来替代人类discriminator,这种方式也在一定程度上固定了discriminator,为generator提供了充足的时间来进行偏好学习。
值得注意的是,在原始的DPO论文中,直接同时学习偏好(discriminator)和行为(generator)的方式被视为一种能够超越PPO学习效率和效果的好方法。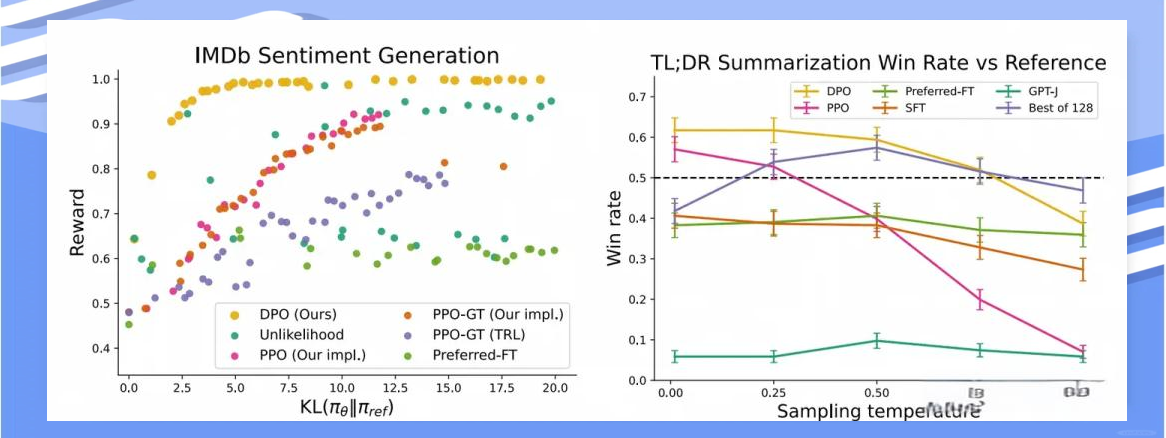
在相同的KL散度条件下,DPO能够获得更佳的Reward,同时在相同的Temperature下,其win rate也更高。这表明DPO在效果上明显优于PPO这种较为复杂的算法。此外,DPO无需训练单独的Reward Model,这使其成为一种快速见效的业务算法。
接下来,我们将深入探讨DPO与RL的更多细节。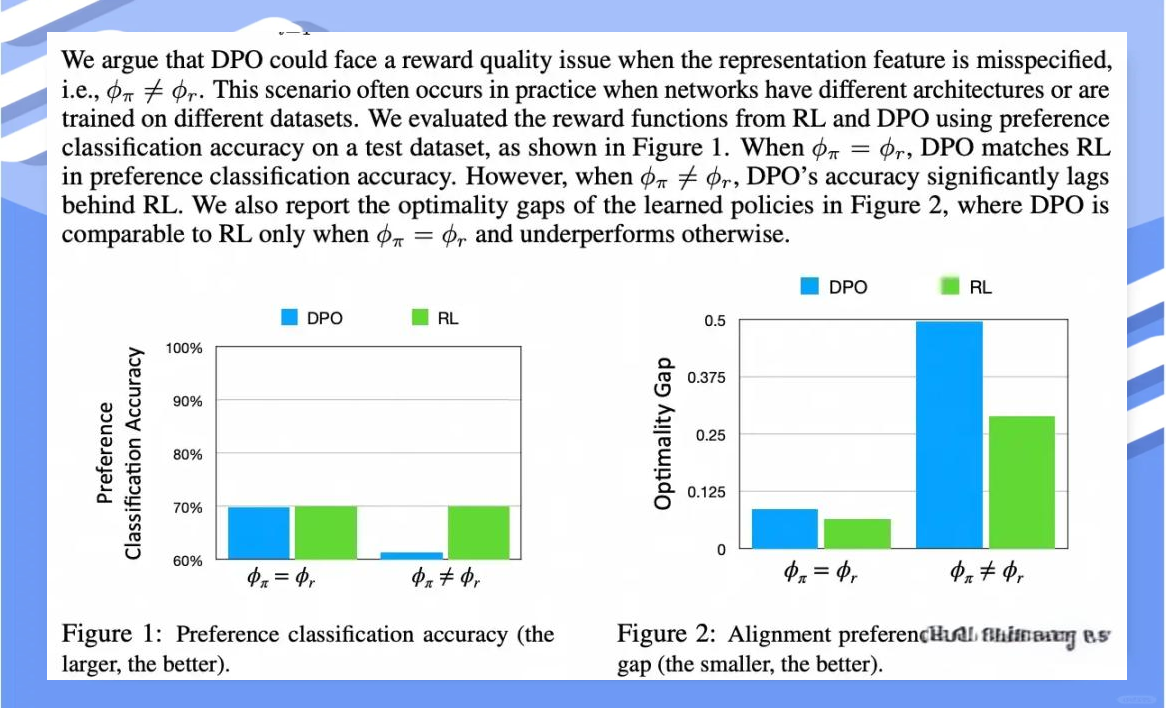
针对DPO在实际业务中可能仍需Reward Model辅助的现象,Ziniu博士在其早期理论建模工作中提供了深入剖析。
他指出,这主要涉及到三个核心问题:
Reward Model建模任务的本质差异
偏好数据不足可能引发的迁移问题
纯离线数据推理所面临的offline performance gap
首先,Reward Model作为神经网络,其核心任务是根据给定的state和action,结合先前对话历史,预测模型最近一轮输出的reward估计值。
而Policy network则是依据当前状态输出相应token的概率,再结合适当的解码策略,进而转化为合适的行动。这两个网络在结构上显然存在差异,而这种差异正是前面所提及的discriminator与generator之间存在gap的基础。
偏好数据不足引发的迁移难题
由于Reward Model的泛化能力,它能够在一定程度上对未见过的状态和行动给出自己的reward判断。然而,对于DPO而言,要在学习行为和判断的同时还要兼顾其泛化,无疑增加了难度。
offline performance gap
在相同的on-policy环境下,在线训练往往能取得更好的效果。传统的DPO在训练初期会采用大量的offline数据进行推理,但随着训练的深入,这些offline数据的off-policy程度会逐渐增高,导致生成的数据与当前优化的policy之间的距离过远,从而难以获得理想的效果。
一些近期实验的案例
Yong Lin在Apple实习期间,深入探讨了DPO的泛化性问题:
这主要是针对上述第二点内容进行实验对比与理论解释。其中,“implicit reward model”这一概念可能较为抽象,但可以简要理解为,我们通过DPO方法,同时学习偏好和行为的方式。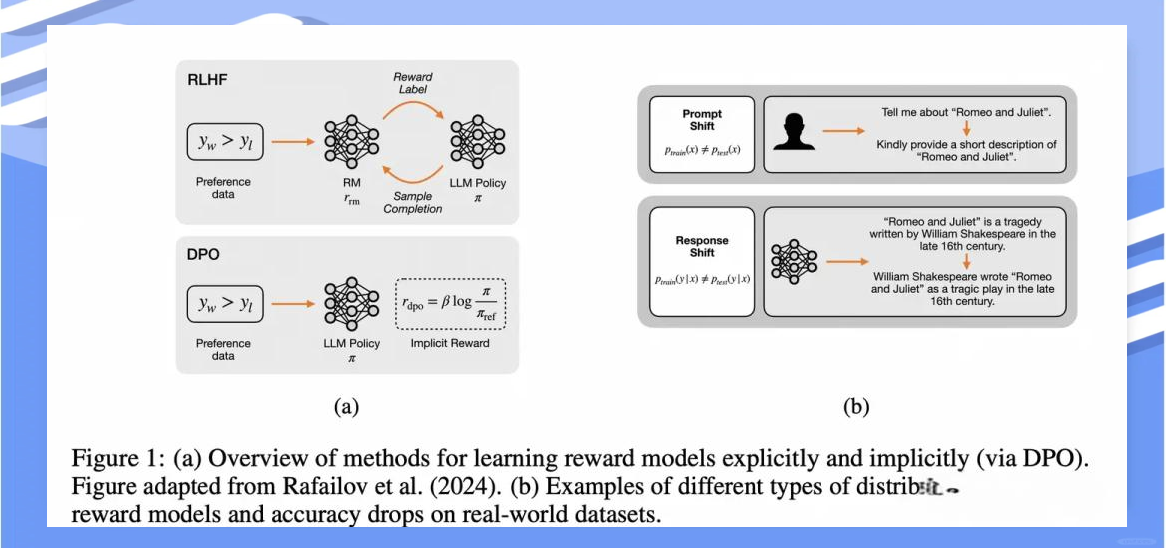
Apple进行此类研究是相当合理的。在面对大量用户时,用户的意图往往错综复杂,同时prompt和response都可能面临distribution shift的挑战。然而,研究的真正目标并非仅仅追求在各种In-distribution榜单上的优异表现。因此,我们可以从其实验结论中汲取有价值的参考。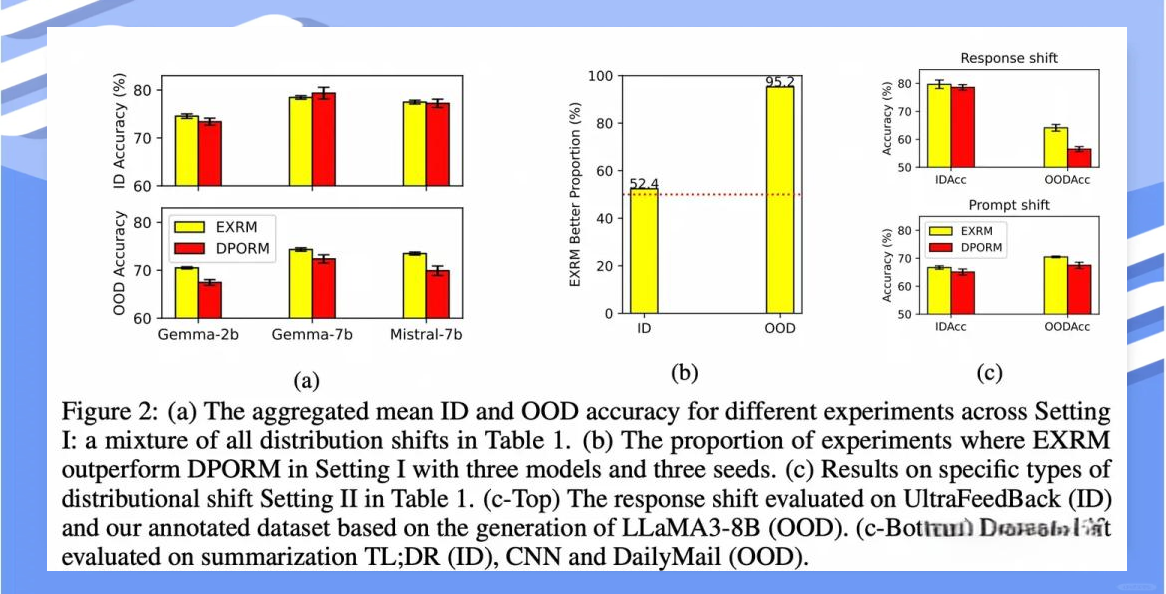
实验概念详解
EXRM:在强化学习(RL)方法中,单独训练出来的奖励模型(Reward Model)。
DPORM:该实验假设,在BT loss之后的DPO训练过程中,能够恢复出奖励值。值得注意的是,DPO本身也可以获得奖励,这一点常被人们忽视,导致直接用策略(policy)进行评测。
实验过程与结果
在保持其他变量一致的前提下,我们对EXRM和DPORM这两种奖励模型建模方法进行了对比实验。实验中,我们引入了prompt shift(奖励模型未曾见过的prompt)和response shift(奖励模型未曾见过的回答)两种挑战情境。结果显示,在ID(in-distribution,即分布内)环境下,DPORM的表现更为出色;然而,当面对OOD(out-of-distribution,即分布外)场景时,RM的精度均出现了显著下滑,尤其是对于OOD的response shift,EXRM的表现更为稳健,明显优于DPORM。此外,在控制变量的OOD实验中,EXRM相较于ID环境下的表现提升了2%。
这一结果进一步印证了我们的第二个实验假设:专注于学习偏好而非同时学习偏好和行为的网络,在效果上似乎更为出色。特别是在强化学习(RL)的扩展性方面,如果仅能通过增加数据量来覆盖偏好,那么构建通用AI系统将面临不小的挑战。
Shusheng Xu在ICML的学术研究中,也探讨了使用DPO学习策略可能面临的问题。这一观点引发了我的进一步思考。
假设我们面临一个需要优化的策略,其中有两个可能的动作,其原始概率分布各占半壁江山。若我们根据个人偏好来调整这个模型,理论上,无论是提升还是降低,这两种优化方式都可以实现。然而,我们需要特别警惕的是,不要提升那些不属于分布范围内的选项,因为这些“意外之选”往往可能带来意想不到的后果。
在DPO优化过程中,为何会出现这种允许提升或降低特定选项的情况呢?
由于DPO的优化目标主要聚焦于通过缩小chosen和reject之间的差距来提升性能,它往往忽视了对分布外样本的考量。这样一来,当遇到优质的分布外样本时,模型可能无法充分利用其价值;而遇到质量不佳的样本时,则可能遭受不必要的损失。
那PPO是否就完全不存在这个问题了呢?我们假设PPO的Reward Model存在问题,它过于乐观地认为分布外的样本是最好的。然而,这并不意味着PPO就没有任何问题。当采样到分布外的答案时,由于这些答案在KL散度约束下被视为异常,会导致KL惩罚极大化,从而消除所有reward的收益。因此,仅仅依赖PPO可能无法充分利用分布外样本的价值。
针对这一问题,一个有效的解决方法是在DPO中加入RM来弥补其泛化性的不足。同时,为了解决offline训练中DPO分布外样本的不足,需要尽可能地使DPO的更新和迭代更接近PPO的online训练方式。从领先玩家的实践来看,迭代式DPO结合RM似乎是一种非常有效的策略。
但这里又出现了一个新问题:如果DPO已经加入了RM、on-policy和online训练,再加上advantage和baseline,那岂不是就变成了纯RL方法了吗?这样的方法比单纯的RL还要更RL,那它为什么还被称为DPO呢?